GPT Image 2.0 Production Benchmark: 13 Use Cases, 34 Generations, 4 Reviewers
Real production scores: 9 of 13 use cases ready without post-processing. Where GPT Image 2.0 leads, where it fails, and how to cut 4K costs by 20×.
GPT Image 2.0 (API name: gpt-image-2) is OpenAI's reasoning-based image generation model, released April 23, 2026. Unlike its predecessor, it runs a planning pass before rendering — a "Thinking mode" that resolves compositional ambiguity, handles text placement, and self-verifies outputs. Within weeks of launch, the production teams at Everypixel were using it daily. This report is what we learned from running it through 34 structured test generations across 13 distinct production use cases — scored by four evaluators using a six-criterion rubric. We're publishing the full data so you don't have to run the same tests yourself.
GPT Image 2.0 belongs in a tiered model stack, not as a default generator. It earns its cost on text-embedded assets, product photography, and multilingual localization — and loses it on volume fill content, crowd scenes, and pixel-exact layout work.
The teams getting the best results in 2026 run Qwen for volume, NanoBanana 2 for iteration speed, and GPT Image 2.0 for hero-tier precision. If that routing fits your deliverable mix, the answer is yes.
- ↑9.8/10 prompt adherence — highest score in our evaluation suite to date
- –9 of 13 categories production-ready without post-processing; 3 borderline; 1 failed
- –Arena Elo 1,512 — 241-point lead over NanoBanana 2, largest gap in Text-to-Image Arena history; 93% win rate in blind eval (The New Stack, April 2026)
- ✓Text rendering: every text-bearing use case production-ready — CJK, Arabic, Cyrillic at small scale — 95%+ accuracy (Segmind, May 2026)
- ✗Crowd scenes fail reliably: UC08 scored 6.9/10 — not correctable through iterative refinement
- ✗Native 4K at $0.41/image is a cost trap — quality=low + upscaler delivers near-equivalent at $0.01–$0.03 (14–40× cheaper)
- –40–90 seconds per output — budget generation time into async workflows
How We Tested GPT Image 2.0
Test design
Test date: May 18, 2026
Model: GPT Image 2.0 (OpenAI, API: gpt-image-2, released April 23, 2026), mode text_to_image, quality=high unless otherwise noted
Total generations: 34 (one generation per use case; 13 use case categories, some with multiple aspect ratios or variations)
Evaluation suite: User Cases T2I v2 — Everypixel's structured image generation test battery
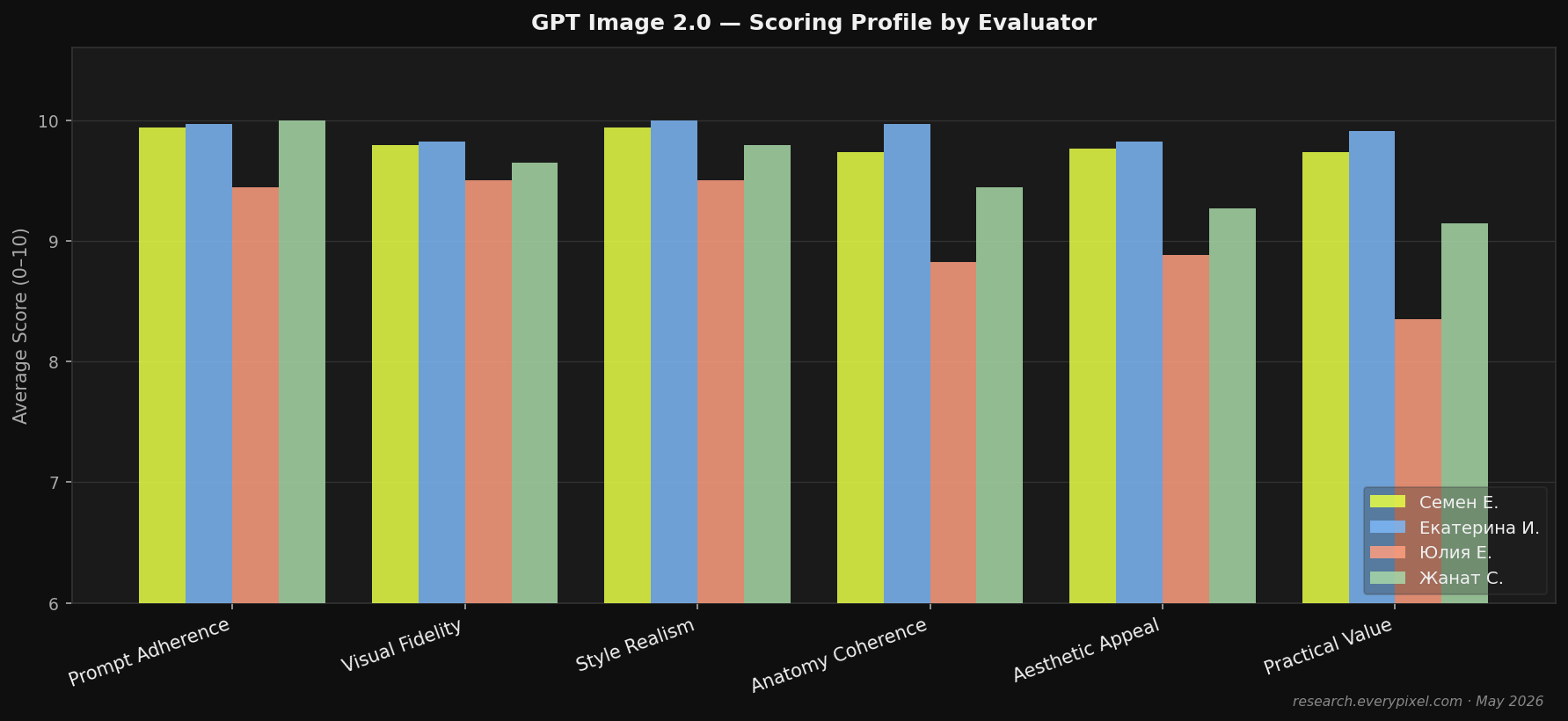
Evaluators: 4 production professionals — Sam E. (creative director), Kate I. (art director), Julia E. (designer), Zhanat S. (photographer)
Each generation was evaluated independently by all four evaluators before scores were compared. Evaluators had no access to each other's ratings or comments during individual assessment.
Scoring criteria (10-point scale):
| Criterion | What it measures |
|---|---|
prompt_adherence | Accuracy of scene execution vs. written prompt |
visual_fidelity | Sharpness, resolution, artifact-free rendering |
style_realism | Believability within the intended style |
anatomy_coherence | Correct proportions, no structural deformities |
aesthetic_appeal | Compositional quality, color harmony, visual engagement |
practical_value | Readiness for production use without post-processing |
All criteria scored 0–10. Final score per use case = mean of 6 criteria × 4 evaluators (24 individual ratings per use case). Production-ready verdict = majority (3+/4 evaluators) rating practical_value ≥ 8.
Content categories tested
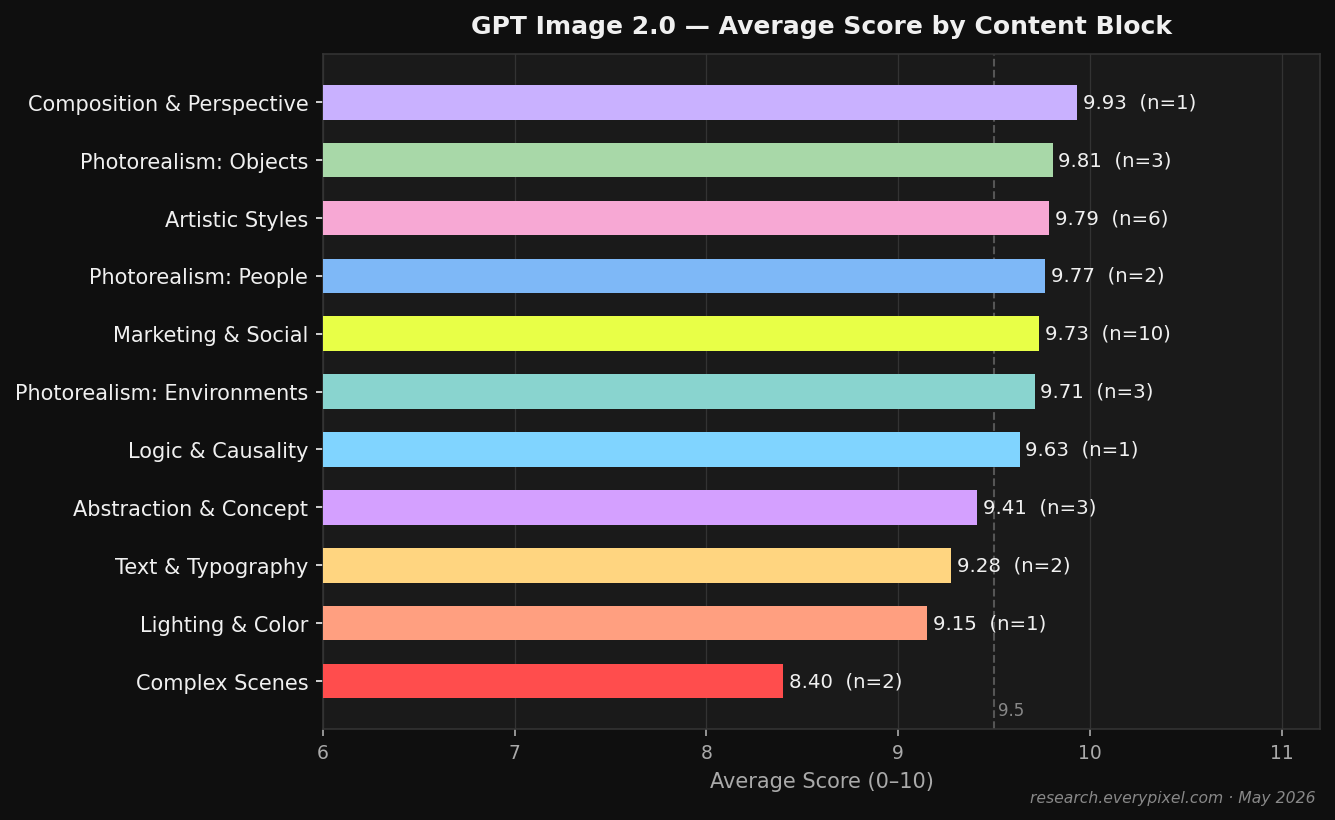
Photorealism: People · Photorealism: Objects and Food · Photorealism: Environments · Composition and Perspective · Text and Typography · Lighting and Color · Complex Scenes · Abstraction and Concept · Artistic Styles · Logic and Causality
External cross-reference sources
Four independent evaluations conducted in the same April–May 2026 window were used for cross-validation on specific findings:
- fal.ai (May 2026): API-layer evaluation — pricing analysis, generation speed benchmarks, quality tiers, direct NanoBanana 2 comparison, color fidelity comparison vs. GPT Image 1.5
- Segmind (May 2026): Multilingual text rendering evaluation — 95%+ accuracy across Latin, CJK, Arabic, Hindi, Bengali; production workflow analysis for content teams
- Atlas Cloud (Q2 2026): Structured 6-category API benchmark — text rendering, geometric transformation, identity consistency, latency; Arena Elo tracking
- Simon Willison (April 2026): Developer evaluation — spatial reasoning stress tests, object location verification, cross-model comparison
Limitations: Everypixel scores reflect subjective evaluation by a 4-person production team focused on stock, advertising, and editorial content. Results should not be extrapolated to fine art, scientific visualization, or architectural CAD contexts. External sources use different methodologies; cross-source comparisons are directional only.
Score Summary
Everypixel production evaluation — 10-point scale, 34 use cases
Everypixel production team · 34 use cases · 4 evaluators · May 18, 2026
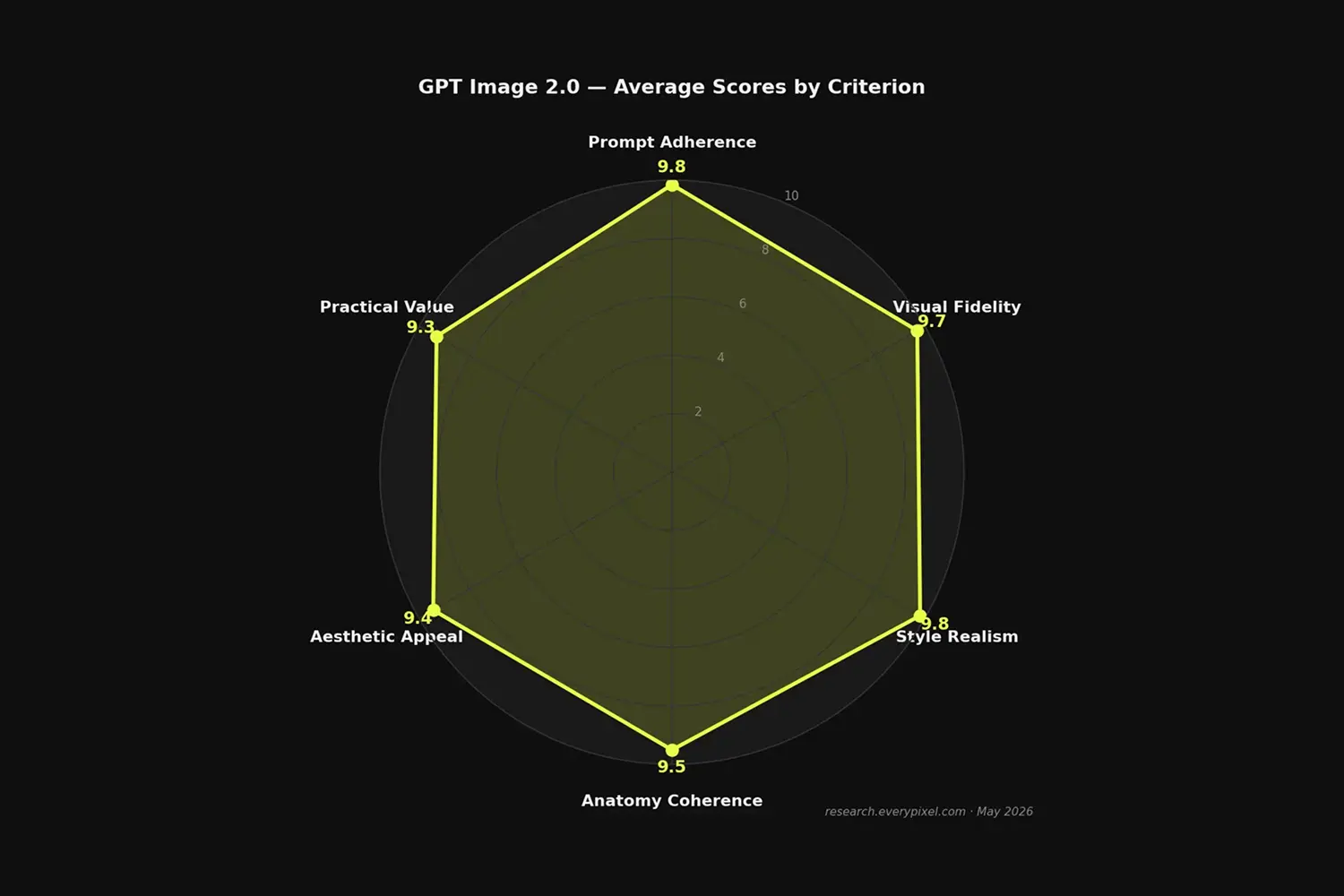
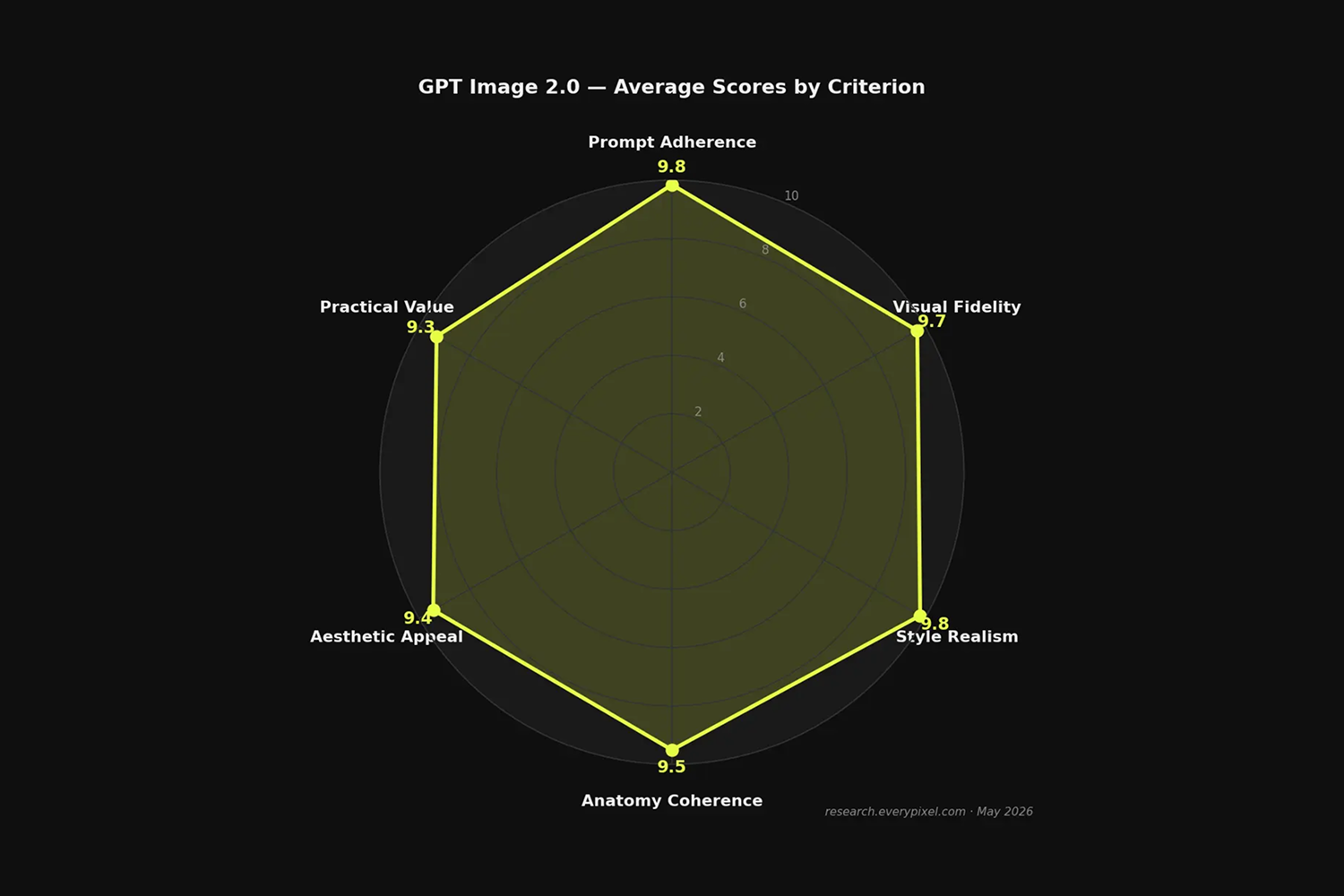
The 0.5-point gap between prompt_adherence (9.8) and practical_value (9.3) reflects the gap between technical execution and production readiness: the model does what it's told at high accuracy, but some outputs require minor adjustment to meet distribution standards. This gap closes further when prompts are well-specified.
Use Case Results
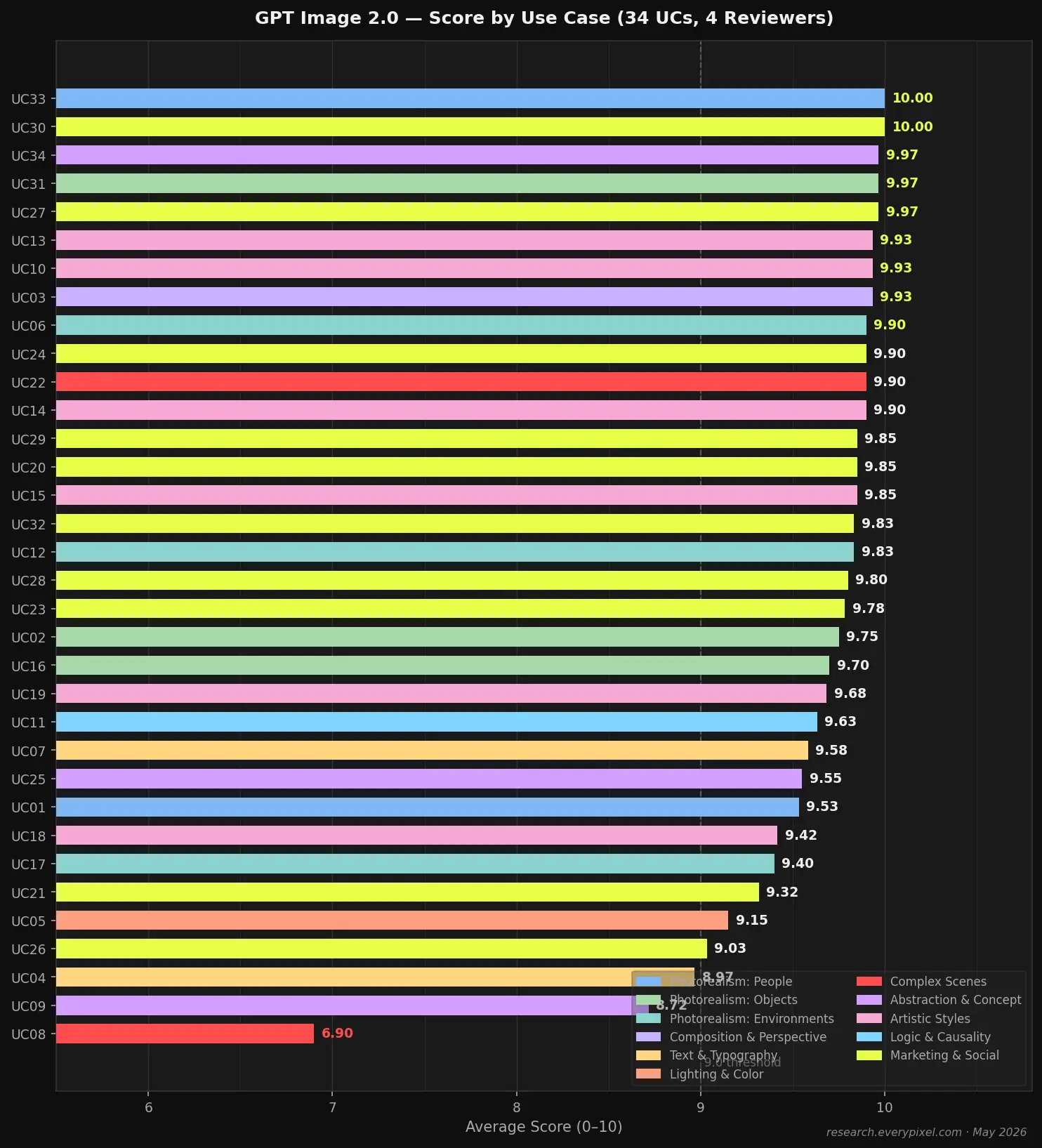
| Use Case | Category | Avg Score | Production-Ready |
|---|---|---|---|
| UC03 — Hero banner / workspace UI | Composition & Perspective | 9.93 | Yes — unanimous |
| UC10 — Fantasy book cover (1:1.5) | Artistic Styles | 9.93 | Yes — unanimous |
| UC06 — Architectural photography | Photorealism: Environments | 9.90 | Yes — unanimous |
| UC12 — Meditation wallpaper (9:19.5) | Photorealism: Environments | 9.83 | Yes — 3/4 |
| UC02 — Luxury perfume product shot | Photorealism: Objects | 9.75 | Yes — unanimous |
| UC11 — Wine pour / physics | Logic & Causality | 9.63 | Yes — 3/4 |
| UC07 — Coffee shop logo | Text & Typography | 9.58 | Yes — 3/4 |
| UC01 — Professional headshot | Photorealism: People | 9.53 | Yes — 3/4 |
| UC05 — Neon cyberpunk portrait | Lighting & Color | 9.15 | Mixed — 3/4 |
| UC04 — YouTube thumbnail (Santorini) | Text & Typography | 8.97 | Mixed — 2/4 |
| UC09 — Sci-fi orbital station | Abstraction & Concept | 8.72 | Mixed — 3/4 |
| UC08 — Tokyo open-air market (crowd) | Complex Scenes | 6.90 | No — 1/4 |
Avg Score = mean of 6 criteria × 4 evaluators. Production-Ready = majority verdict on practical_value. 12 representative use cases shown; full 34-UC dataset available on request.
Findings
Finding 1: Text and typography — no other model does this reliably in a single pass
What we tested and what we saw:
- UC03 (hero banner, laptop with dashboard UI on screen): All four evaluators rated
practical_value10/10. Sam E.: "Excellent work with text, even with small text. Even the text on screen reads correctly." The dashboard interface visible through the laptop screen rendered as a plausible, readable UI — not a blurred approximation. - UC07 (coffee shop logo, "VOLTA COFFEE" arched in curved vintage serif): Three of four evaluators confirmed production-ready. The primary concern was downstream vectorization, not legibility — the letterforms were correctly rendered.
- UC10 (fantasy book cover with title line and author name at 1:1.5 format): The model adapted to the non-standard aspect ratio without explicit pixel dimensions and placed typographic elements correctly at cover scale. Sam E.: "Even when given a horizontal aspect ratio by default, the model oriented itself and made the correct cover."
External validation:
- Segmind (May 2026): 95%+ text rendering accuracy across Latin, Japanese, Korean, Chinese, Hindi, and Bengali — "the first image model practical for shipping multilingual marketing assets without manual redraw." One editor can produce 10 regional variants of a thumbnail in under an hour. Limitation documented: very long body copy degrades past 3–4 lines.
- Atlas Cloud (Q2 2026): "Rendered every word — from large headlines to small-print footnotes — with 100% correct spelling and zero character bleeding" across all structured text rendering tests.
- fal.ai (May 2026): Korean pojangmacha signage rendered with correct character construction in a dedicated CJK stress test, consistent with our findings.
Our verdict: If your workflow includes images with embedded text — packaging, branded social content, UI mockups, book covers, multilingual localization — route everything through GPT Image 2.0. The post-processing step that every other model requires here is eliminated.
Finding 2: Product photography — commercial quality, zero studio
What we tested and what we saw:
- UC02 (luxury perfume bottle, polished marble surface, lateral lighting, water droplets, legible product label): Kate I.: "Looks like professional photography. Reflections, droplets, text all handled well. Can be used in work immediately." Average: 9.75/10, unanimous production-ready verdict.
- UC11 (red wine being poured into crystal glass, frozen splash mid-air, label reading "RESERVA 2018"): Sam E. noted the matching font between the bottle label and adjacent title card as "evidence of design capability in this model." Average: 9.63/10, three of four evaluators production-ready.
The wine pour result confirms basic pour physics at production grade. Complex fluid dynamics — continuous splashing, perfume misting across frames — should be validated per-prompt rather than assumed consistent.
Our verdict: For e-commerce catalogs, advertising product shots, and editorial objects, GPT Image 2.0 eliminates the need for product photography sessions on the majority of SKUs. Plan for per-prompt spot-checking on scenes with complex dynamic fluid behavior.
Finding 3: Architectural geometry — passed the parallel lines test
UC06 (modern residential facade, glass and concrete, 35mm wide-angle distortion from street level): average 9.90/10, unanimous production-ready verdict. Sam E.: "Even examining the generation very closely and analyzing it in detail, it is almost impossible to find generative artifacts in the image. This model passes the difficult test of parallel fine lines in architecture with excellence."
Our verdict: Real estate listings, architectural portfolio renders, and property development visuals are production-viable. This is not the case for most AI image models as of mid-2026.
Finding 4: Color fidelity — the yellow filter artifact is eliminated
fal.ai measured this directly: color accuracy on white and near-white surfaces improved substantially versus GPT Image 1.5, reducing the downstream correction burden that made the predecessor unreliable for packaging and UI contexts.
Everypixel evaluators raised no color cast issues across any of the 13 use cases, consistent with fal.ai's findings.
Our verdict: Product photography and brand content requiring color accuracy — white backgrounds, neutral product surfaces, packaging — no longer requires color correction as a standard post-processing step. This alone justifies the model for e-commerce workflows where white-background product shots are a volume deliverable.
Finding 5: Complex crowd scenes — confirmed failure ceiling, not fixable
UC08 (Tokyo open-air market at dusk, dozens of people, Japanese and English signage, photojournalistic style, f/8 sharp throughout): Average 6.9/10 — the lowest score in the full suite. The atmospheric and text elements were evaluated positively; the crowd rendering was not.
- Zhanat S.: "Artifacts and strange things in several faces. Text is legible, strange sign on building glass in the background. The atmosphere is there."
- Julia E. rated all six criteria 1/10: "Too many people in the distance, almost all identical and walking in one direction, some faces are distorted."
From the Everypixel team's production experience: inpainting passes on crowd scenes do not resolve face artifacts — they redistribute them. Plan your workflow around selection from multiple first-pass generations, not iterative correction.
Our verdict: Multi-person crowd scenes and photojournalistic street photography are not production-reliable with GPT Image 2.0. This is not a solvable problem through prompting or post-processing. Route crowd-heavy content to licensed stock; reserve AI generation for controlled portrait and small-group scenarios where anatomy coherence is testable.
Where to Spend and Where to Save
API pricing reference
| Resolution | Low quality | Medium quality | High quality |
|---|---|---|---|
| 1024 × 768 | $0.01 | $0.04 | $0.15 |
| 1024 × 1024 | $0.01 | $0.06 | $0.22 |
| 3840 × 2160 (4K) | $0.02 | $0.11 | $0.41 |
Source: OpenAI API pricing, verified May 2026. Verify current rates before production decisions — pricing subject to change.
Why quality=high costs 22× more than quality=low
The price gap reflects architecture, not a quality slider. GPT Image 2.0 operates in two modes. In Thinking mode (quality=high), the model reasons through composition, resolves prompt ambiguity, can query web references during generation, and self-verifies outputs before returning a result (The New Stack, April 2026). In Instant mode (quality=low), this reasoning pass is skipped. For complex scenes, text rendering, and material physics, Thinking mode produces measurably better output. For thumbnails, background fills, and exploratory generations, it doesn't — and the cost difference is unjustifiable at volume.
The math that matters
| Workflow | Cost per image | 50-image run |
|---|---|---|
| GPT Image 2.0 — quality=high, 1024×1024 | $0.22 | $11.00 |
| GPT Image 2.0 — quality=low + upscaler | ~$0.01–$0.03 | $0.50–$1.50 |
| Route hero assets to high, volume to low+upscale | Blended | ~$2–$3 |
Spend quality=high on: hero assets, packaging, typography-critical work, product shots going into a campaign, anything where a single output is the deliverable.
Save with quality=low + upscaler on: concept exploration, volume catalog generation, social fill content, thumbnails, deck visuals, internal content.
How GPT Image 2.0 compares on speed and 4K pricing
NanoBanana 2 (fal.ai data): generates approximately 60 seconds faster per image at equivalent quality settings; 4K high quality at $0.16 vs. $0.41; supports up to 14 reference images and 5-person character consistency across a batch. For workflows requiring high-resolution variants at speed, NanoBanana 2 is the economically rational choice. GPT Image 2.0 remains the better choice where text rendering, material fidelity, and prompt accuracy are the priority.
GPT Image 2.0 Decision Matrix: Which Task Gets Which Model
| Task | Recommendation | Reasoning |
|---|---|---|
| Product photography — objects, packaging, glass/metal | First choice | 9.75/10 in testing; material fidelity at commercial standard |
| Hero banners with embedded text or dashboard UI | First choice | practical_value 10/10 unanimous; text-on-screen readable |
| Book covers, editorial typography layouts | First choice | Correct aspect ratio adaptation; typographic hierarchy handled |
| Architectural photography and real estate | First choice | Parallel lines test passed; 9.90/10 in testing |
| Multilingual packaging and localization | First choice | CJK, Arabic, Cyrillic confirmed at small scale |
| Professional headshots and brand portraits | Strong choice | 9.53/10; test against your brand aesthetic first |
| Logo and brand concept generation | Good | Legible output; plan a vectorization step downstream |
| Concept art and narrative illustration | Good | Strong prompt fidelity; aesthetic preferences vary by evaluator |
| High-volume iteration, 50+ images/session | Secondary | NanoBanana 2 is faster; use GPT Image 2.0 for final hero only |
| 4K output at volume | Cost-optimize | quality=low + upscaler reduces cost ~20×; test quality match first |
| Crowd scenes, multi-person street photography | Not recommended | 6.90/10; failure pattern confirmed; not correctable |
| Precision graphic design — layout, spacing, grids | Not recommended | Prompt language is insufficient for pixel-exact layout control |
For Production Agencies
Batch production and throughput:
The 40–90-second generation window means GPT Image 2.0 does not fit synchronous, real-time request handling. For agencies running batches of 50–200 assets per client per month, this matters less than it does for teams expecting immediate iteration — queue-based generation with async delivery is the appropriate architecture. NanoBanana 2's ~60-second speed advantage per image compresses batch timelines meaningfully; use it for concept iteration and GPT Image 2.0 for final hero output.
Brand consistency across a batch:
Brand consistency at volume requires prompt engineering rather than native reference image features. For batches requiring locked character or product identity across outputs, NanoBanana 2 supports up to 14 reference images and 5-person identity consistency — a structural advantage GPT Image 2.0 does not have. GPT Image 2.0's advantage is per-image quality on text-embedded and material-fidelity tasks, not cross-image consistency.
The cost math for agency production:
At 200 images/month per client, routing all through quality=high (1024×1024) costs $44/month per client in API costs alone. Routing 20% hero assets through quality=high and 80% volume through quality=low + upscaler brings this to approximately $6/month per client — with no perceptible quality loss on social and web delivery formats.
Agency routing logic:
For Social Media Teams
Format coverage across platforms:
Everypixel tested the vertical 9:19.5 aspect ratio (Reels/Shorts format) at UC12 — 9.83/10, production-ready in 3 of 4 evaluations. Horizontal and square formats performed at equivalent or higher scores across the suite. The 1:1.5 book ratio adapted correctly at 9.93/10 without explicit pixel dimensions in the prompt. Social format coverage is not a constraint with this model.

Where iteration speed becomes a problem:
At 40–90 seconds per generation, GPT Image 2.0 is not built for rapid A/B iteration where a designer needs 15–20 variants to find a winner. For exploration and variant generation, NanoBanana 2's ~60-second speed advantage per image compounds meaningfully across a session. The practical workflow: use NanoBanana 2 for the exploration phase, use GPT Image 2.0 to produce the final approved asset.
The strongest argument for social teams: text overlays in a single pass:
For posts requiring a headline, CTA, or branded callout embedded in the image — the format that currently requires a Canva or Figma step after AI generation — GPT Image 2.0 produces a finished output without that additional step. Every text-bearing test in the Everypixel suite cleared the production-ready bar. For a content calendar heavy on text-embedded formats, this is a direct workflow compression.
Social content routing:
For B2B Marketing Teams
Where GPT Image 2.0 is production-ready for B2B content:
- Professional headshots and executive portraits: 9.53/10, production-ready in 3 of 4 evaluations. Validate against brand aesthetic before volume deployment.
- Office and architectural environments: 9.90/10, unanimous verdict. Headquarters photography, real estate, event venue mockups — all viable.
- UI and product dashboard mockups: 9.93/10, unanimous. Readable screen content, plausible interface layouts — sufficient for sales decks, product pages, and stakeholder review.
- Presentations and thought leadership graphics: text-embedded designs produced in a single pass; typography is legible at slide and screen scale.
Compliance: EU AI Act Article 50 and C2PA
From August 2026, EU AI Act Article 50 requires visible disclosure labeling and machine-readable C2PA metadata for AI-generated images distributed in the EU — regardless of which model generates them. B2B teams distributing content to EU clients or publishing to EU-accessible platforms need to build C2PA tagging and disclosure workflows into their production pipeline before the enforcement deadline. Non-compliance: fines up to €15M or 3% of global annual revenue. This is not a future consideration; it requires infrastructure decisions now.
Approval workflow and the practical_value gap:
The 0.5-point gap between prompt_adherence (9.8) and practical_value (9.3) is the number that matters most for B2B approval cycles: GPT Image 2.0 produces technically correct outputs that may still require a review pass before executive or client distribution. Build that review step into the workflow. The model is a strong first draft, not a guaranteed final — and in a B2B context where outputs reach external stakeholders, the distinction matters.
What GPT Image 2.0 does not replace for B2B:
Precision layout work — annual reports, formal brand documents, multi-page collateral — still requires human design execution. The model communicates direction well; it does not execute to brand standards without human oversight. Use it for concepting and mockup; hand off final layout to a designer.








UC 25, 26, 27, 28, 29, 30, 31, 32, 33
External Validation
Frequently Asked Questions
quality=low ($0.01–$0.02/image) and chain into an upscaler. fal.ai documents this achieving near-4K output at a fraction of the $0.41 native 4K cost. The quality=low setting disables the full reasoning pass but retains structural and compositional quality sufficient for upscaler input in most use cases. Test your specific content type before committing to this path at volume.Evaluator Agreement and Variance
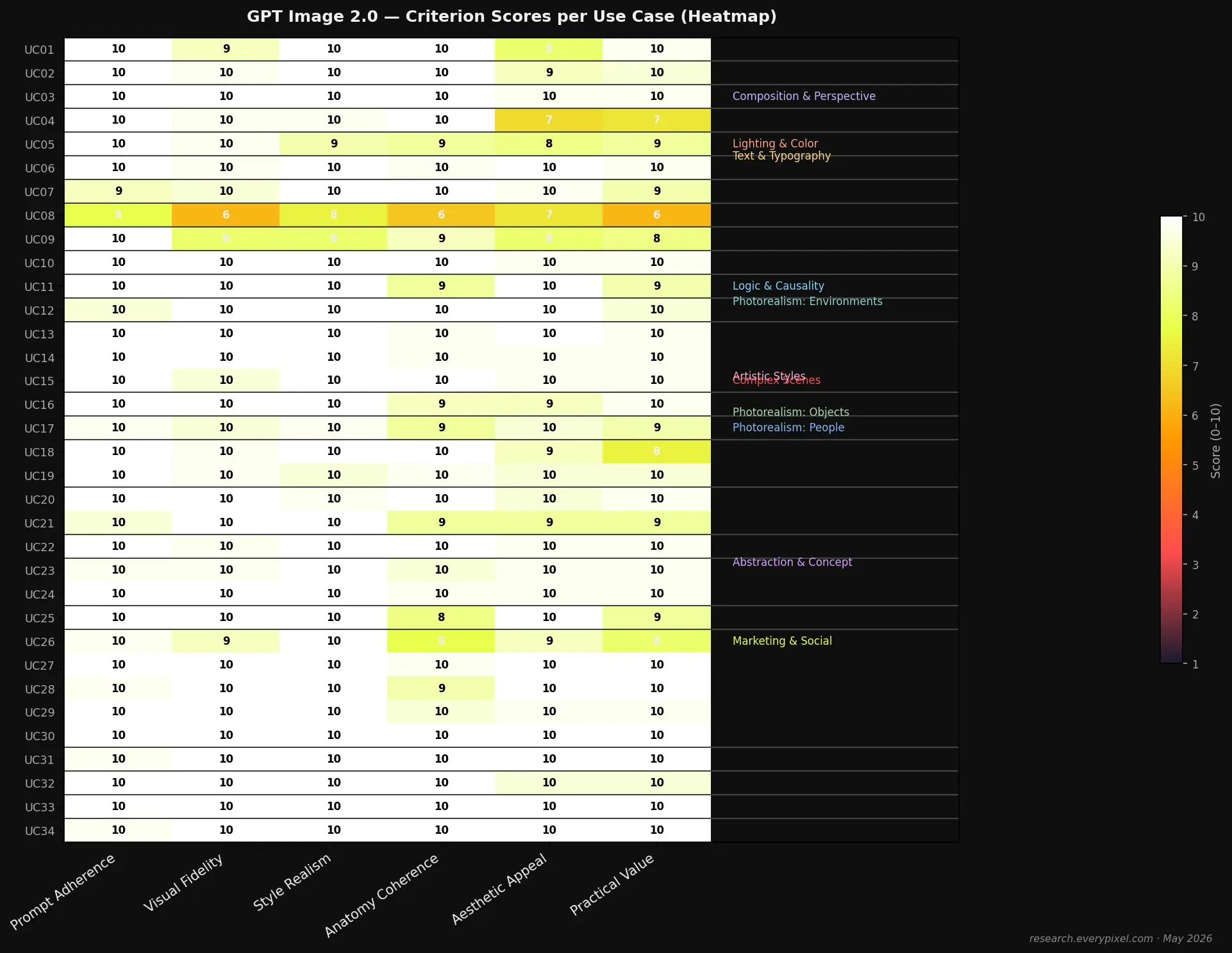
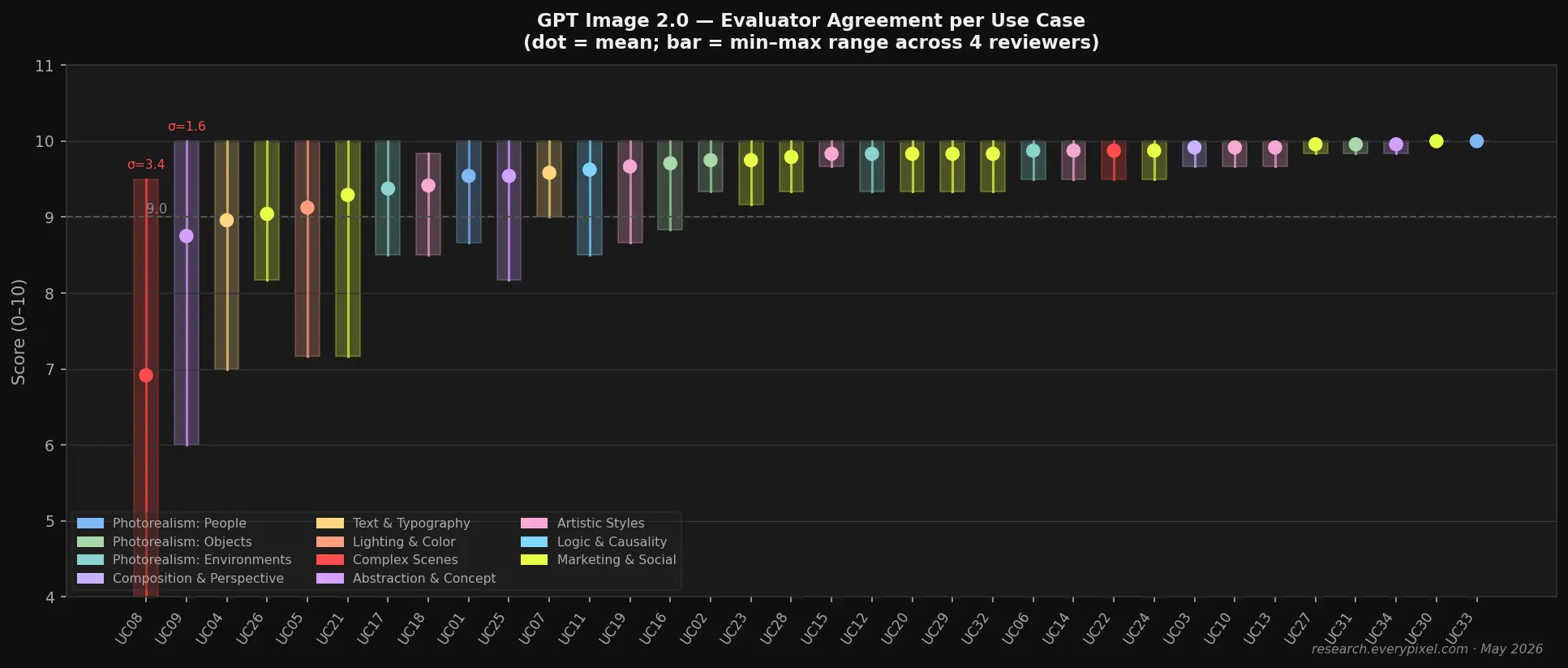
The highest evaluator variance in the suite occurred in UC08 (crowd scene, σ = 3.8 across all criteria) and UC09 (sci-fi concept art, σ = 1.2 on aesthetic_appeal). The crowd scene variance reflects genuine disagreement about atmospheric success versus rendering failure: two evaluators weighted the successfully-rendered atmosphere and signage; two evaluators weighted the face artifacts and crowd repetition. Both readings are defensible; the practical implication is the same — the output is not universally production-ready.








UG 10, 19, 20, 22, 23, 24
About This Test
Everypixel operates Workroom, a platform where production teams generate, select, and license AI-generated visual content. research.everypixel.com publishes structured model evaluations based on the team's daily production experience. Rankings on this page reflect production usability as evaluated by working professionals — not marketing claims, synthetic benchmarks, or cherry-picked outputs.
Raw test data (prompts, per-evaluator scores, evaluator comments) available on request for research purposes. All scores dated May 18, 2026. Pricing data verified May 2026 via fal.ai and OpenAI API documentation — verify current rates before production deployment.
Cite this article
<blockquote cite="https://research.everypixel.com/gpt-image-2-0/"> <p>Real production scores: 9 of 13 use cases ready without post-processing. Where GPT Image 2.0 leads, where it fails, and how to cut 4K costs by 20×.</p> <footer>— <a href="https://research.everypixel.com/gpt-image-2-0/">GPT Image 2.0 Production Benchmark: 13 Use Cases, 34 Generations, 4 Reviewers</a>, Everypixel Research, May 2026</footer> </blockquote>
Everypixel Research. (2026). GPT Image 2.0 Production Benchmark: 13 Use Cases, 34 Generations, 4 Reviewers. research.everypixel.com. https://research.everypixel.com/gpt-image-2-0/